Amazon Web Services (AWS): Textract: Points to remember
Let's learn about Amazon Textract:
-
Textract is a document analysis service that detects and extracts text, structured data and tables from images and scans of documents.
-
Textract's ML models have been trained on millions of documents so that virtually any document type users upload is automatically recognized & processed for text extraction.
-
Textract can detect Latin-script characters from the standard English alphabet and ASCII symbols.
-
Textract currently supports PNG, JPEG, and PDF formats.
-
Textract supports logging of the following actions as CloudTrail events - DetectDocumentText, AnalyzeDocument, StartDocumentTextDetection, StartDocumentAnalysis, GetDocumentTextDetection & GetDocumentAnalysis.
-
Textract charges users based on the number of pages and images processed.
-
Data from Textract is encrypted and stored at rest in the AWS region where users are using Textract.
-
Textract is compliant with SOC-1, SOC-2, SOC-3, ISO 9001, ISO 27001, ISO 27017 and ISO 27018.
-
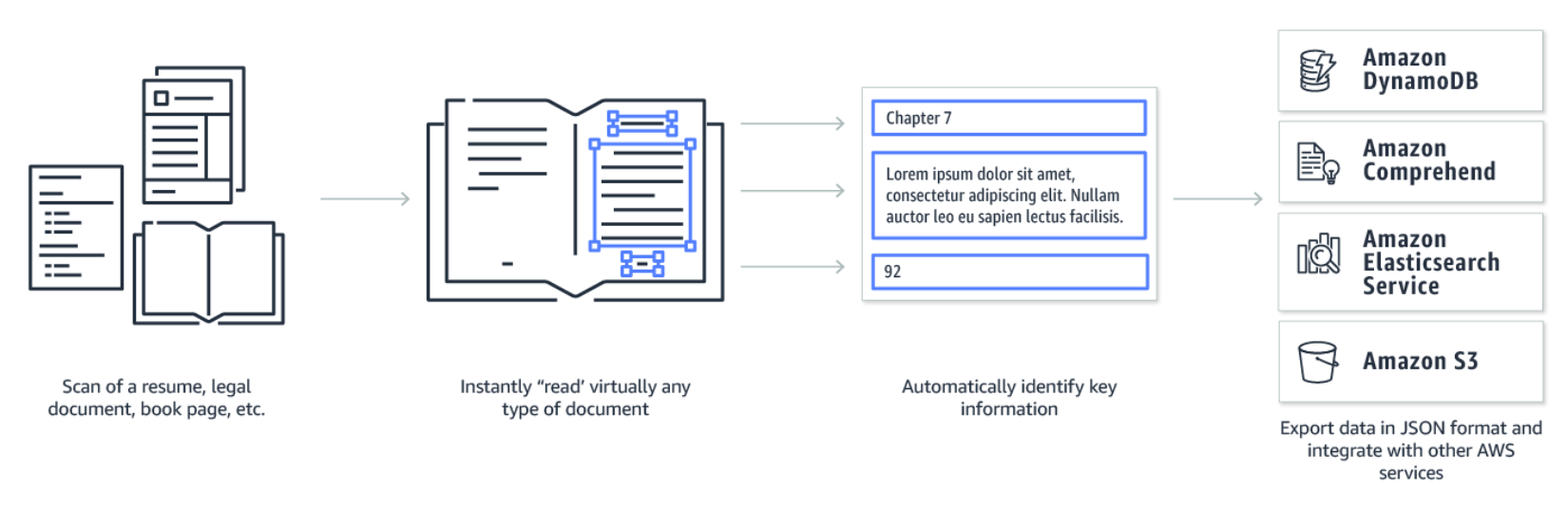
Textract uses Optical Character Recognition (OCR) technology to automatically detect printed text and numbers in a scan or rendering of a document, such as a legal document or a scan of a book.
-
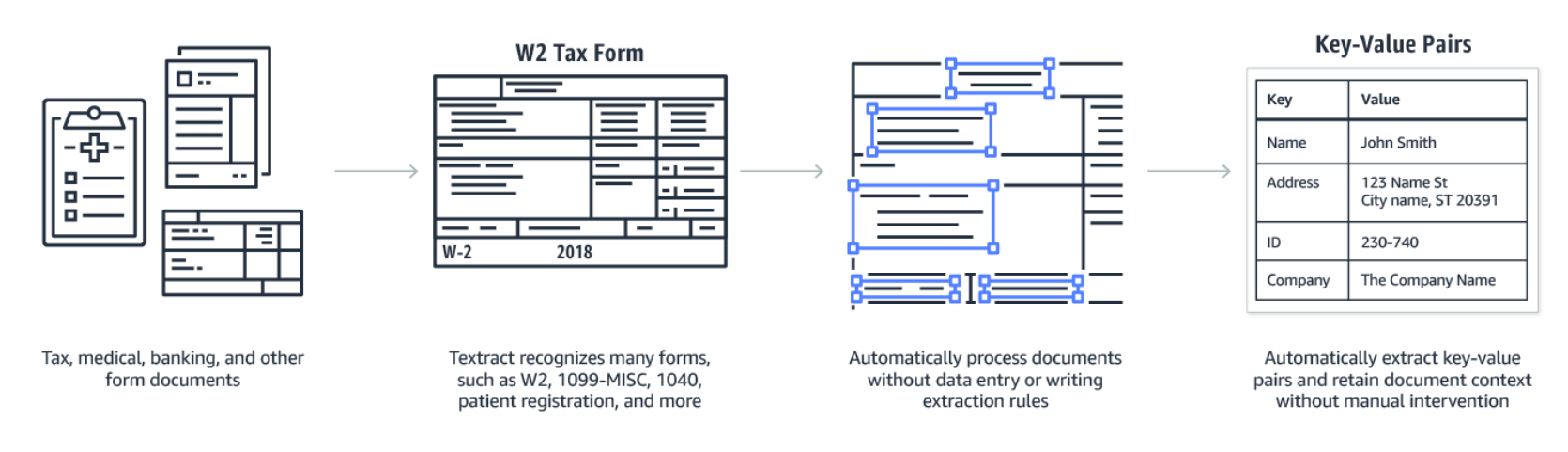
Textract enables users to detect key-value pairs in document images automatically so that they can retain the inherent context of the document without any manual intervention.
-
Textract preserves the composition of data stored in tables during extraction.
-
Textract is directly integrated with Amazon A2I so users can easily implement human review of text extracted from documents.
-
Users can easily process millions of documents using Textract's text extraction APIs.
-
With synchronous processing, Textract can analyze single-page documents for applications where latency is critical.
-
Textract provides asynchronous operations to extend support to multipage documents.
-
With AWS Batch, Textract is able to process multiple document images in a single operation.
-
To detect text asynchronously, use StartDocumentTextDetection to start processing an input document file.
-
To detect text synchronously, use the DetectDocumentText API operation and pass a document file as input.
-
Textract analyzes documents and forms for relationships between detected text.
-
Textract analysis operations return three categories of text extraction: text, forms and tables
-
For Textract synchronous operations, users can use input documents that are stored in S3 bucket, or they can pass base64-encoded image bytes.
-
Textract can detect selection elements such as option buttons and check boxes on a document page.
-
Textract conforms to the AWS shared responsibility model, which includes regulations and guidelines for data protection.
-
Textract communicates exclusively via HTTPS endpoints, which are supported in all Regions supported by Textract.
-
Textract is protected by the AWS global network security procedures.
A Points to remember series by Piyush Jalan.