Amazon Web Services (AWS): Athena: Points to remember
Let's learn about Amazon Athena:
-
Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
-
Athena is serverless, so there is no infrastructure to setup or manage & user can start analyzing data immediately.
-
Athena uses Presto with full standard SQL support and works with a variety of standard data formats, including CSV, JSON, ORC, Apache Parquet and Avro.
-
Users can use Athena to generate reports or to explore data with business intelligence tools or SQL clients, connected via an ODBC or JDBC driver.
-
Athena can be accessed via the AWS Management Console, an API or an ODBC or JDBC driver.
-
Athena can handle complex analysis, including large joins, window functions and arrays.
-
User can invoke their SageMaker machine learning models in an Athena SQL query to run inference.
-
With User-Defined Functions (UDFs), users can now write their own functions in Java and invoke them in Athena SQL query.
-
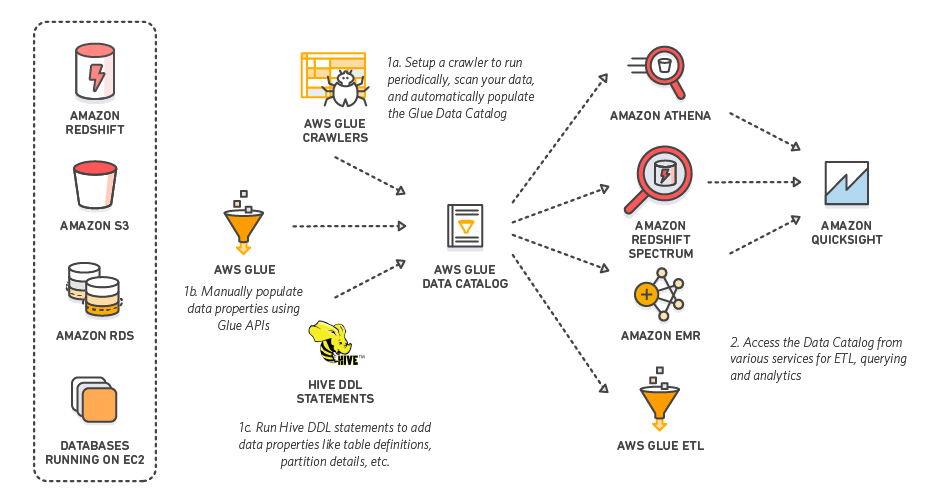
Users can connect Athena to their external Apache Hive Metastore.
-
Athena uses Apache Hive DDL to define tables.
-
Athena supports compressed data in Snappy, Zlib, LZO and GZIP formats.
-
Athena supports both simple data types such as INTEGER, DOUBLE, VARCHAR and complex data types such as MAPS, ARRAY and STRUCT.
-
Users can run ANSI-Compliant SQL SELECT statements to query their data in Amazon S3.
-
Athena uses SerDes (Serializer/Deserializer) to interpret the data read from Amazon S3.
-
Parquet and ORC files created via Spark can be read in Athena.
-
Athena allows users to partition their data on any column.
-
Athena integrates with Amazon QuickSight, allowing users to easily visualize their data stored in Amazon S3.
-
Athena has open sourced data source connectors to Apache HBase, Amazon DocumentDB, Amazon DynamoDB and Amazon CloudWatch Logs and CloudWatch Metrics.
-
All Athena query results are stored in an Amazon S3 location that user set.
-
Athena allows users to control access to their data by using AWS IAM policies, Access Control Lists (ACLs) and Amazon S3 bucket policies.
-
Athena integrates with KMS and provides users an option to encrypt their result sets.
-
Athena is priced per query and charges based on the amount of data scanned by the query.
-
Users can save 30%-90% on their query costs and get better performance by compressing, partitioning & converting their data into columnar formats.
-
Users are not charged for failed queries.
-
If user cancel a query manually, they are charged for the amount of data scanned up to the point at which they cancelled the query.
A Points to remember series by Piyush Jalan.