Amazon Web Services (AWS): Glue: Points to remember
Let's learn about Amazon Glue:
-
Glue is a fully-managed, pay-as-you-go, extract, transform & load (ETL) service that automates the time-consuming steps of data preparation for analytics.
-
It also allows users to setup, orchestrate & monitor complex data flows.
-
Users should use Glue to discover properties of the data their own, transform it & prepare it for analytics.
-
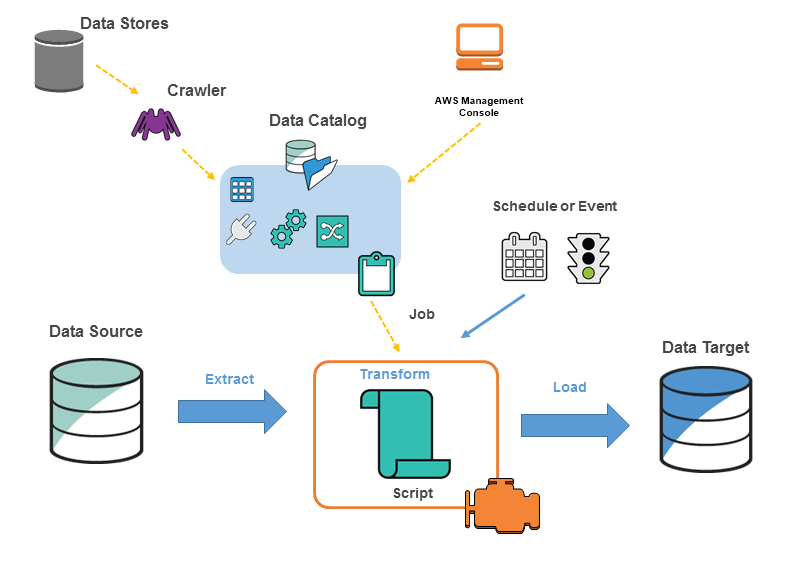
Glue automatically generates Scala or Python code for users ETL jobs that they can further customize using tools they are already familiar with.
-
The metadata stored in the Glue Data Catalog can be readily accessed from Athena, EMR & Redshift Spectrum.
-
The AWS Glue Data Catalog is a central repository to store structural and operational metadata for all data assets.
-
Users can import custom Python libraries and Jar files into AWS Glue ETL job.
-
Glue provides a robust set of orchestration features that allow users to manage dependencies between multiple jobs to build end-to-end ETL workflows.
-
Glue ETL jobs can either be triggered on a schedule or on a job completion event.
-
Glue manages dependencies between two or more jobs or dependencies on external events using triggers.
-
Glue consists of a Data Catalog which is a central metadata repository, an ETL engine that can automatically generate Scala or Python code, and a flexible scheduler that handles dependency resolution, job monitoring & retries.
-
Glue can automatically discover both structured and semi-structured data stored in data lake on S3, data warehouse in Redshift & various databases running on AWS.
-
The AWS Glue Data Catalog is Apache Hive Metastore compatible and is a drop-in replacement for the Apache Hive Metastore for Big Data applications running on Amazon EMR.
-
Glue crawlers scan various data stores users own to automatically infer schemas and partition structure and populate the Glue Data Catalog with corresponding table definitions and statistics.
-
Glue monitors job event metrics and errors & pushes all notifications to CloudWatch.
-
Glue ETL is batch oriented & users can schedule their ETL jobs at a minimum of 5 min intervals.
-
Glue's FindMatches ML Transform makes it easy to find and link records that refer to the same entity but don’t share a reliable identifier.
-
Glue works on top of the Apache Spark environment to provide a scale-out execution environment for data transformation jobs.
-
Glue SLA guarantees a Monthly Uptime Percentage of at least 99.9% for AWS Glue.
-
Glue takes a data first approach and allows users to focus on the data properties and data manipulation to transform the data to a form where they can derive business insights.
-
Users can use AWS Glue to build a data warehouse to organize, cleanse, validate & format data.
-
Glue supports data encryption at rest for Authoring Jobs in AWS Glue and Developing Scripts Using Development Endpoints.
-
AWS provides Secure Sockets Layer (SSL) encryption for data in motion. Users can configure encryption settings for crawlers, ETL jobs & development endpoints using security configurations in AWS Glue.
-
A development endpoint is an environment that users can use to develop and test their AWS Glue scripts.
-
AWS Glue tags Amazon EC2 instances with a name that is prefixed with aws-glue-dev-endpoint.
A Points to remember series by Piyush Jalan.