Amazon Web Services (AWS): Redshift: Points to remember
Let's learn about Amazon Redshift:
-
Redshift is a fast, fully managed data warehouse that makes it simple & cost-effective to analyze all data using standard SQL & existing BI tools.
-
Redshift allows to run complex analytic queries against petabytes of structured data, using sophisticated query optimization, columnar storage on high-performance local disks & massively parallel query execution.
-
Redshift gives fast querying capabilities over structured data using familiar SQL-based clients & BI tools using standard ODBC and JDBC connections.
-
Redshift supports VPC, SSL, AES-256 encryption & Hardware Security Modules to protect data in transit and at rest.
-
Redshift Spectrum is a feature of Redshift that enables to run queries against exabytes of unstructured data in S3, with no loading or ETL required.
-
Redshift manages all the computing infrastructure, load balancing, planning, scheduling & execution of queries on data stored in S3.
-
Users can load data into Redshift from a range of data sources including S3,DynamoDB,EMR,Glue,Data Pipeline and or any SSH-enabled host on EC2 or on-premises.
-
Redshift will automatically detect and replace a failed node in user's data warehouse cluster.
-
Redshift replicates all user's data within their data warehouse cluster when it is loaded and also continuously backs up their data to S3.
-
Redshift always attempts to maintain at least three copies of data (the original and replica on the compute nodes and a backup in S3).
-
Redshift can also asynchronously replicate snapshots to S3 in another region for disaster recovery.
-
Redshift enables automated backups of data warehouse cluster with a 1-day retention period.
-
Concurrency scaling is a feature in Redshift that provides consistently fast query performance, even with thousands of concurrent queries.
-
Elastic Resize adds or removes nodes from a single Redshift cluster within minutes to manage its query throughput.
-
Redshift Spectrum supports many open source data formats, including Avro, CSV, Grok, Ion, JSON, ORC, Parquet, RCFile, RegexSerDe, SequenceFile, TextFile & TSV.
-
Redshift Spectrum supports Gzip and Snappy compression.
-
The CREATE EXTERNAL SCHEMA command supports Hive Metastores. AWS do not currently support DDL against the Hive Metastore.
-
Redshift Spectrum queries run using per-query scale-out resources against data in S3.
-
Redshift periodically performs maintenance to apply fixes, enhancements and new features to cluster.
-
For Redshift, users are billed based on: Compmute node hours, Backup Storage, Data transfer, Data scanned.
-
Users can also use Redshift Spectrum together with EMR. Redshift Spectrum uses the same approach to store table definitions as Amazon EMR.
-
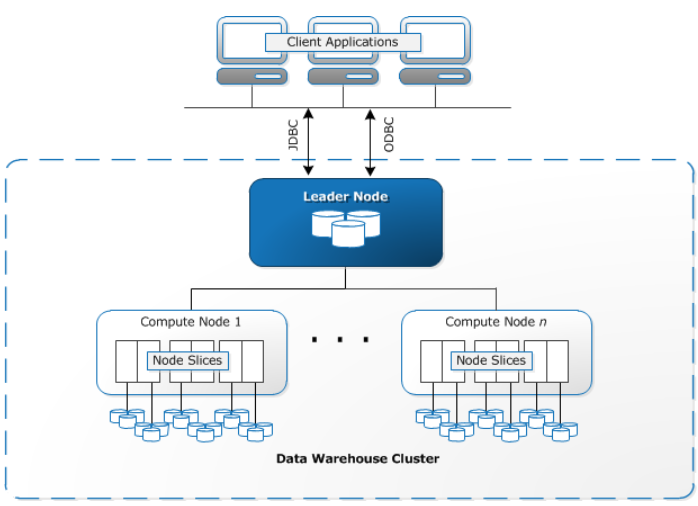
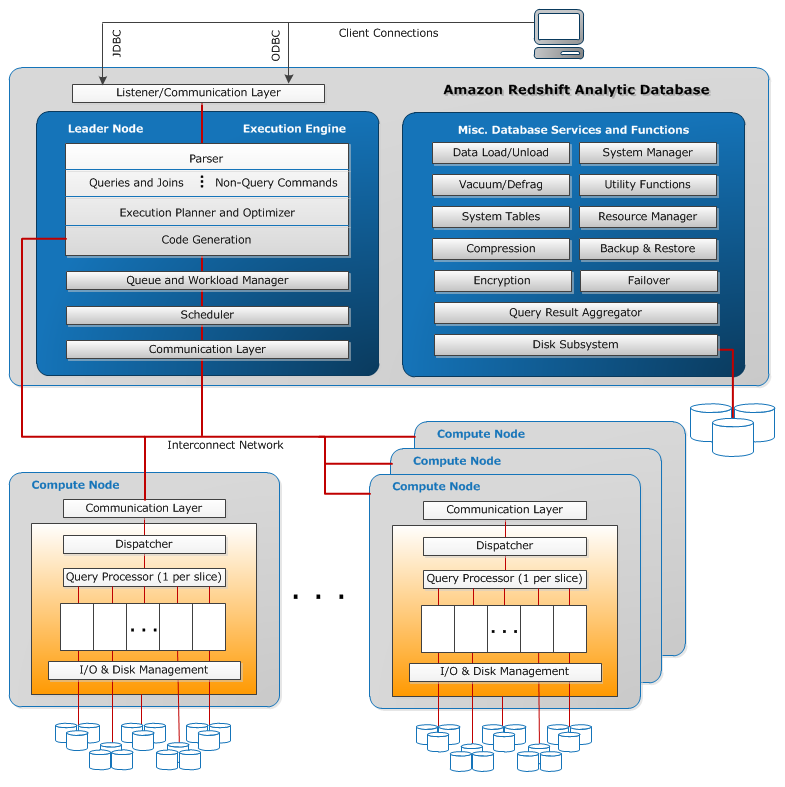
In Redshift, a leader node receives queries from client applications, parses the queries and develops execution plans, which are an ordered set of steps to process these queries.
-
In Redshift, compute nodes execute the steps specified in the execution plans and transmit data among themselves to serve these queries.
-
Redshift uses a variety of innovations to achieve up to ten times higher performance than traditional databases for data warehousing and analytics workloads: Columnar Data Storage, Advanced Compression, Massively Parallel Processing (MPP), Redshift Spectrum.
-
Redshift automatically distributes data and query load across all nodes.
A Points to remember series by Piyush Jalan.